Shazam听歌识曲算法解析+python实现-3 检索歌曲
第三部份
在开始之前,我们首先要认真阅读一下论文《An Industrial-Strength Audio Search Algorithm》。
paper下载链接:https://www.ee.columbia.edu/~dpwe/papers/Wang03-shazam.pdf
中文翻译:https://blog.csdn.net/yutianzuijin/article/details/49787551
建议读英文的鸭。
为获得良好的阅读体验,你可能先需要了解 mysql数据库的基础知识,python基础语法,一定的代码阅读能力,一定的语文理解能力(up写的很乱)。
好的,那么今天我们进入最后一部分,搜索与匹配。
Up在这里使用了orm框架SQLalchemy
首先,我们要建立起一个数据库来储存上一步中获取的指纹信息。
其中一个表来储存歌曲信息,一个表来储存歌曲信息对应的指纹,两个表用歌曲的id作为外键相连。
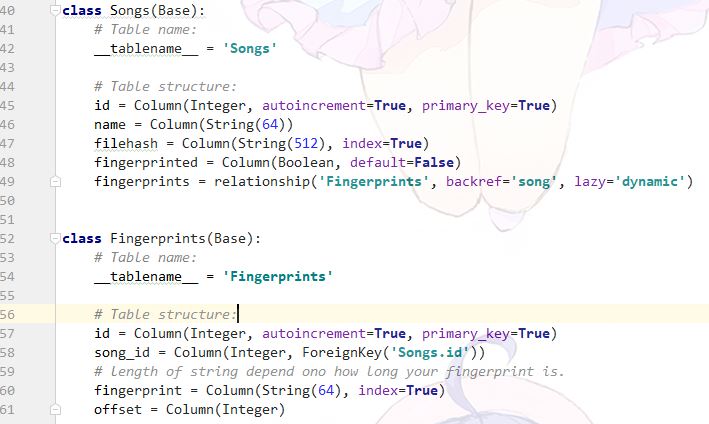
注意,fingerprint 这个column 必须要加上index,这将会大大减少查询速度,千真万确。
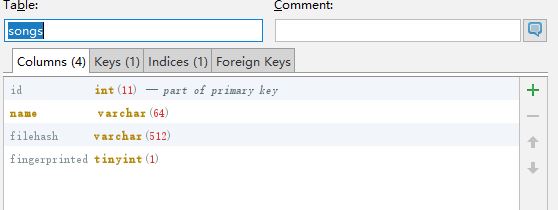
songs 表为歌曲信息表:
id 用来储存歌曲id,
name用来存储歌曲名字
filehash用来储存该歌曲文件的哈希
fingerprinted用来判断该歌曲是否已经进行了fingerprint
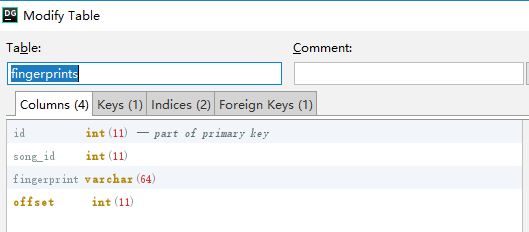
Fingerprints 表为储存指纹的表:
id为指纹id,没什么用
song_id 是外键,记录对应的歌曲信息
fingerprint就是获取到的指纹信息
offset就是该指纹的offset位置
建完这个表,然后你就可以把指纹信息全都放进去了。
然后,我们来讲讲搜索与识别的基本原理:
1.首先输入一段声音,然后和之间一样,获取这一段声音的指纹。
2.对获取到的每一个指纹,在数据库中搜索相同的指纹,并将指纹对应的歌曲信息,以及offset偏移值保存。
3.有相同offset差值越多的歌曲就是识别出的歌曲。
tk’=tk+offset,
这样子说可能有点抽象,我们来举个栗子:
假如在某个音频中,你提取到了1个指纹,这个指纹是 c19dde0ecb8fca81b6c98d5ee3775c26cbb32a610c82a5ecda515b0beb86d357, 且它在那段音频中的offset 是 30。
通过这个指纹,你在数据库中取到了如下的数据
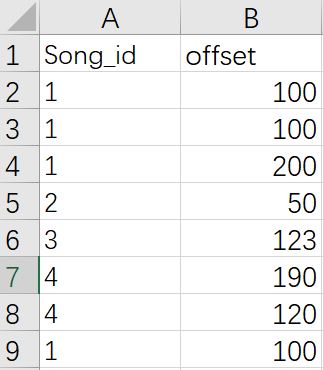
然后我们可以计算得到 offset 差值分别为 70, 70 ,170, 20, 93, 160, 90, 70
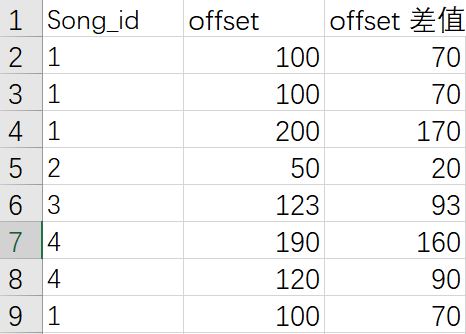
在这里,我们可以看到,offset差值是70 且 id 为 1 的有3 个,offset差值是170 且 id 为 1的有一个,offset差值是20 且 id 为 2 的有1 个,offset差值是933 且 id 为 3 的有一个……
所以最多就是 有3个的那个值。也就是id为1的歌曲。
有人会问,为什么不一首歌一首歌的检索呢,因为慢。
接下来代码。
获取所有匹配的指纹,并将歌曲信息与offset差值保存下来。

对数据进行处理,得出相同offset差值最多的歌曲,也就是识别出来的歌曲。
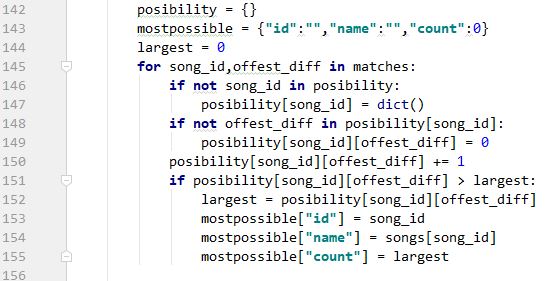
结束。
转载请先获得许可