喜马拉雅xm文件解密逆向分析 [Electron]
前言
说点前言,但是我又不知道说啥了。
由于最近突然喜欢在做事情的时候开个有声小说,于是我就把喜马拉雅这个软件重新下载了下来,并小冲了一个会员。
我注意到喜马拉雅这个客户端同时具有下载的功能,小小的尝试了一下,发现下载下来的文件为.xm文件格式。这个格式属于一种加密的格式,除了喜马拉雅客户端之外都不能播放。
什么,加密的?这怎么能忍。
仅限于学习交流使用,本文作者不负任何其他责任
Disclaimer: Only used for educational purpose.
动态分析
Electron自带的参数可以很好的帮助我们对electron程序进行动态分析。
electron在运行的时候一般会有两个process。一个为main process,另外一个为render process
在调试这个程序的时候,主要需要调试的main process。 所以我们可以加上--enable-logging来显示main process中console.log的内容。
同时,我们也可以用--inspect=9000 + chrome v8 debugger 的方式进行调试。
在使用inspect的时候需要给main.prod.js加上一个patch,不然启动不了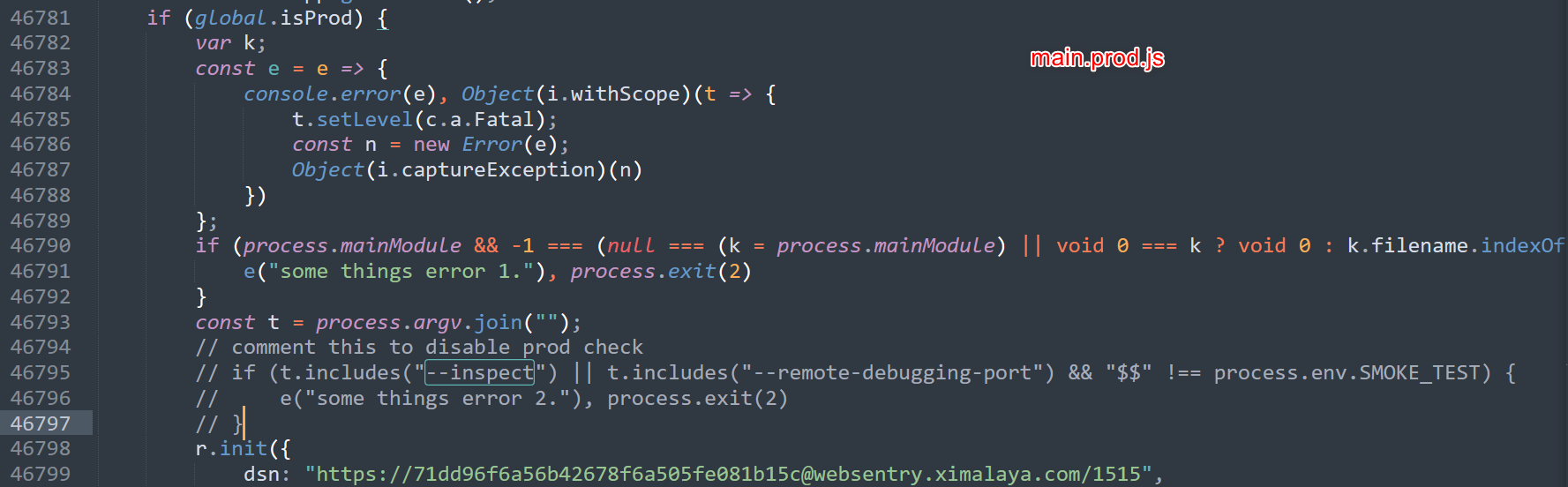
如果我们需要对 render process 进行调试,我们可以在代码中加上
const { BrowserWindow } = require('electron')
const win = new BrowserWindow()
win.webContents.openDevTools()并重新打包app.asar。
当然,喜马拉雅app提供了另外一个flag --xmdebugger来启动render process的debugger

具体可以看 Reference Section
分析过程
首先来看一眼文件结构,ok,一眼electron,直接解压app.asar开破。
app.asar 在 resourses 目录下,解压之后发现了一堆文件。
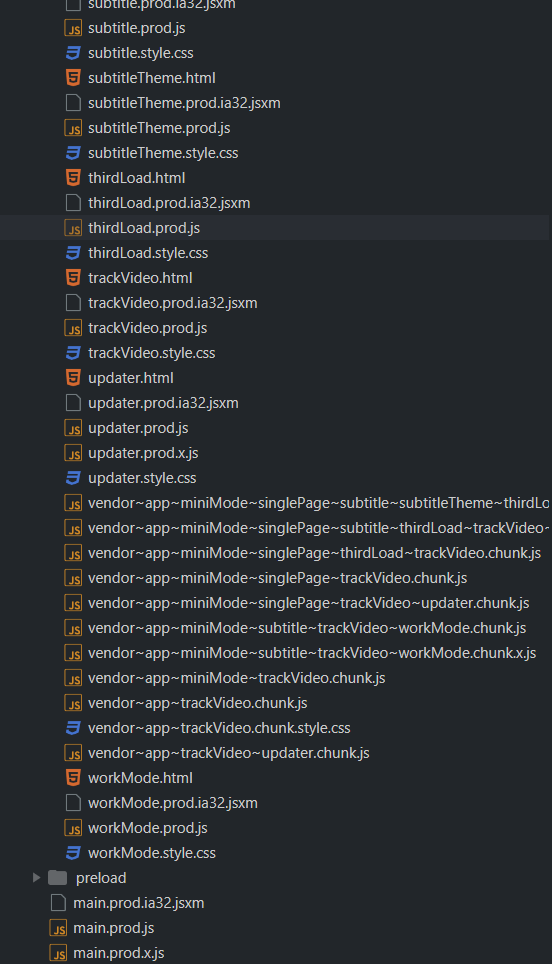
总之在经过一番寻找之后,我定位到了几个和解密加密有关的重要javascript文件。
24.chunk.js 以及 updater.chunk.js。(和加密解密完全无关的名字,这就是混淆么)
首先我们用js-beautify来格式化代码,不然代码在都在一行里分析起来太折磨了。
关于
js-beautify的安装使用可以参考js-beautify
updater.chunk.js
updater.chunk.js
n.e(24).then(n.bind(null, 1297)).then(e => {
window.xmDecrypt = e.ext_xm_decode, window.xmEncrypt = e.ext_xm_encode
});
// ignored
// ignored
// ignored
// ignored
// ignored
class N extends u.WriteStream {
constructor(e, t, n, r) {
super(e), C(this, "tags", void 0), C(this, "info", void 0), C(this, "iv", void 0), C(this, "chunkCount", void 0), this.tags = n, this.info = t;
const o = this.tags.ISRC || this.tags.encodedBy || "";
this.iv = Buffer.from(o, "hex"), this.chunkCount = 0
}
// 加密函数
write(e, t) {
let n = e;
if (this.chunkCount < 1) {
const r = e.slice(0, 12).toString("base64"),
o = e.slice(12).toString("base64");
try {
console.log("restChunk", o, o.length, this.info.trackId);
console.time("加密耗时:");
const e = window.xmEncrypt(o, "" + this.info.trackId);
console.log(e);
console.timeEnd("加密耗时:"), e || t("下载遇到了问题,保存失败");
console.log(`[nodeEncrypt] trackId:${this.info.trackId}, iv: ${this.iv.toString("hex")}`);
const a = function(e, t) {
const n = m.a.createCipheriv("aes-256-cbc", Buffer.from(j), t);
let r = n.update(e);
return r = Buffer.concat([r, n.final()]), r
}(e, this.iv),
i = a.length,
s = {
...this.tags,
encodingTechnology: r,
size: i
},
l = I.a.create(s);
n = Buffer.concat([l, a])
} catch (e) {
throw console.error("handle audio buffer error: ", e), e
}
}
return this.chunkCount++, super.write(n, t)
}
}
// ignored
// ignored
// ignored
// ignored
// ignored
function U(e, t) {
t = t.toString();
const n = Buffer.alloc(16, t.slice(0, 16));
let r = "";
const o = m.a.createDecipheriv("aes-192-cbc", Buffer.alloc(24, t), n);
return r += o.update(e, "base64"), r += o.final(), r
}
var L = n(234);
// 解密函数
var Q = () => {
const e = (e, {
filePath: t,
trackId: n,
decryptVersion: r
}) => {
try {
// console.log(`[nodeDecrypt] trackId: ${n}, decryptVersion:${r}`);
// NODEID3
const o = f.a.readFileSync(t),
a = I.a.getTagsFromBuffer(o);
if (!a || n && +a.trackNumber !== n) throw new Error("incorrect track");
// console.log(a.title,a.size);
const {
title: s,
artist: l,
subtitle: c,
length: d,
comment: {
language: u,
text: p
},
album: h,
trackNumber: b,
size: g,
encodingTechnology: v,
ISRC: _,
fileType: y,
encodedBy: w,
publisher: k,
composer: x,
mediaType: S
} = a;
n = +b;
const E = I.a.removeTagsFromBuffer(o);
console.log(`[nodeDecrypt] trackId: ${n}, iv:${_||w}`);
const P = function(e, t) {
const n = e,
r = m.a.createDecipheriv("aes-256-cbc", Buffer.from(j), t);
let o = r.update(n);
return o = Buffer.concat([o, r.final()]), o
}(E.slice(0, +g), Buffer.from(_ || w, "hex")).toString(),
q = ("12" == r ? U : window.xmDecrypt)(P, "" + n);
// console.log(P);
console.log(q);
// console.log(`[nodeDecrypt] ${"12" == r}, ${r}`);
if (!q) throw new Error("parse track error");
let C = v + q;
C = Buffer.concat([Buffer.from(C, "base64"), E.slice(g)]);
const N = new Blob([Object(L.a)(C)]),
O = {
trackName: s,
anchorName: l,
albumId: +c,
duration: +d,
trackCoverPath: p,
trackId: n,
albumTitle: h,
src: URL.createObjectURL(N),
isPaid: "paid" === y,
deviceId: k,
type: S || ""
};
i.ipcRenderer.sendTo(e.senderId, "reply-track-decrypt-message", O)
} catch (t) {
console.warn("de audio error: ", t), i.ipcRenderer.sendTo(e.senderId, "reply-track-decrypt-error-message")
}
};
return i.ipcRenderer.on("track-decrypt-message", e), () => {
i.ipcRenderer.removeListener("track-decrypt-message", e)
}
};首先,从加密函数中可以看出,xm文件加密只加密了文件的第一个chunk,其余的chunk都是以明文储存的。
在解密函数也能看出这一点,在解密了以一个chunk的数据后,他直接把这个数据和接下来的数据concat在一起了,没有再做别的处理。
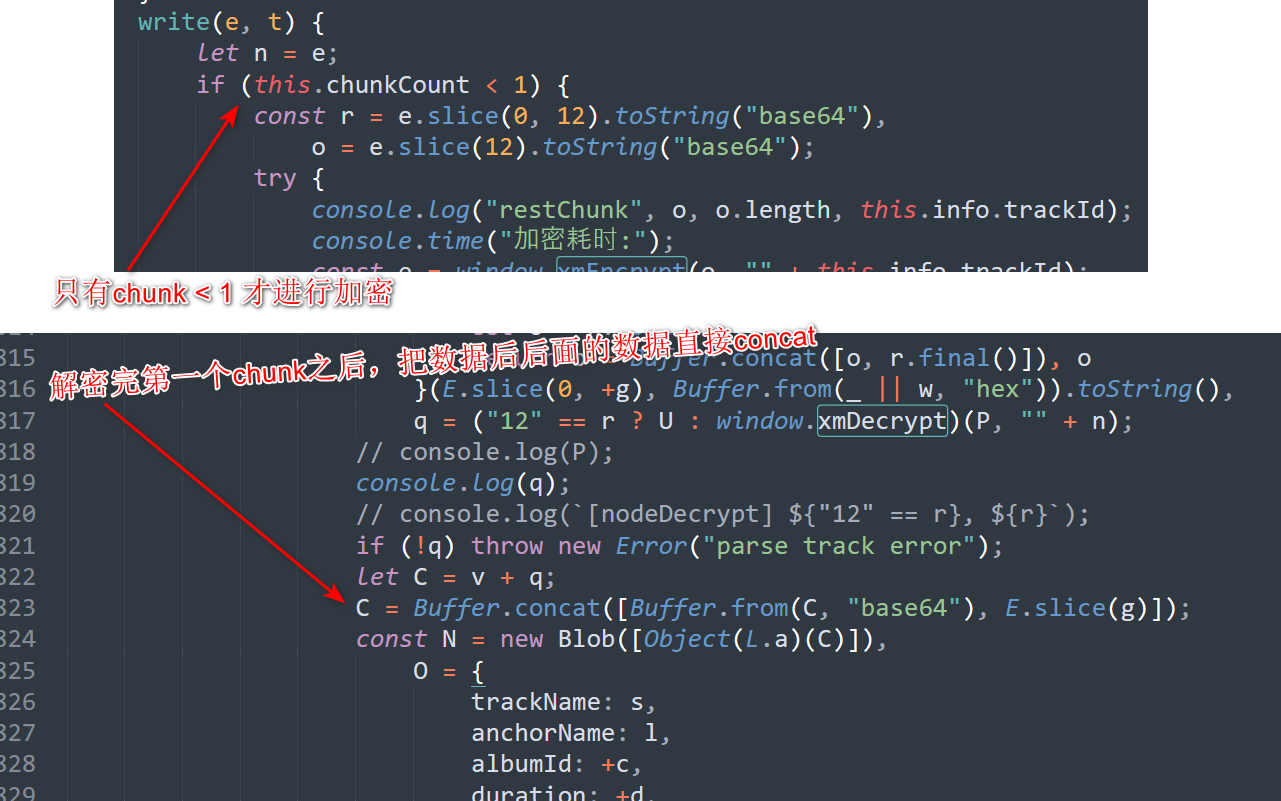
再来看看解密函数,解密的过程本身十分好懂
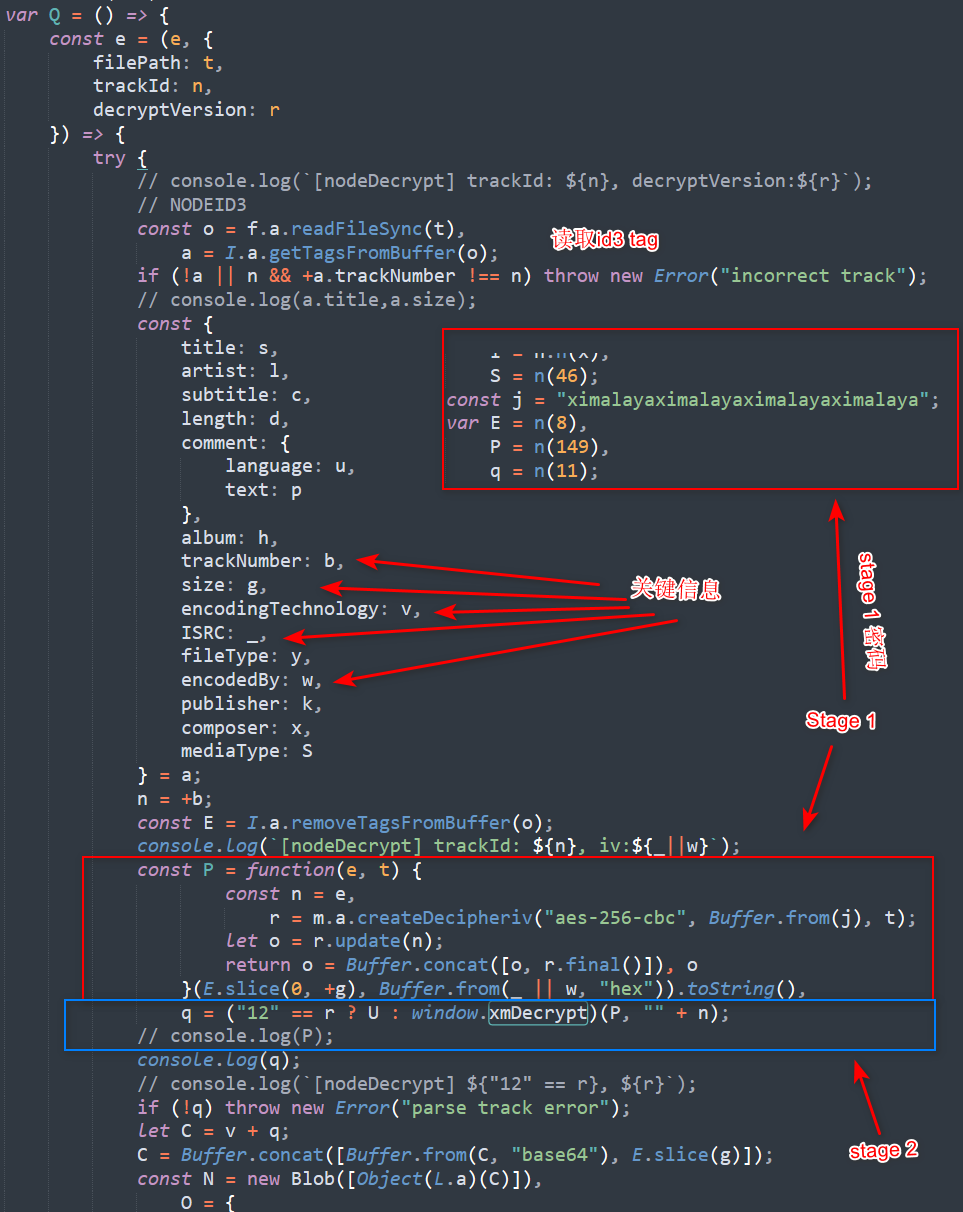
我们可以大致把解密的过程分为四个stage
Stage 0: 第一个stage就是读取ID3tag,来获取必要的信息。
通过getTagsFromBuffer和removeTagsFromBuffer这两个函数,我们可以推测出,喜马拉雅使用了node-id3这个开源库来读取文件头的id3 tags。
同时,观察后面的代码,我们也能发现这个解密函数使用了以下tag的值对数据进行解密。
trackNumber, size, encodingTechnology, ISR, encodedBy
在读取tag之后,解密函数会把tag数据从原始数据中删除,只保留数据部分。
Stage 1: aes-256-cbc。
首先通过id3 tag中的size值获得被加密的数据长度 (也就是第一个chunk的长度)。 用slice把这部分数据拿出来。
然后看ISRC和encodedby这两个值。获取其中不为空字符串的值。把这个值以16进制进行读取,可以获得一个byte array。
接下来就可以对这部分加密数据进行解密了,把这个byte array作为iv,加上一个固定的key,用aes-256-cbc解密这个数据,可以获取到一段base64编码的数据。
这个数据将作为第三个stage的数据,进行进一步解密。
完成stage 1的解密之后,这个解密函数会判断decryptVersion是多少。如果decryptVersion为"12"那么就使用U这个解密函数,不然则使用window.xmDecrypt这个解密函数。
根据我的试验,最新版中所有的decryptVersion都不等于"12"(可能会有例外,但我遇到的都不是"12")。
在获得对应的函数之后,解密函数会把上一步中获得数据以及tracknumber作为两个字符串参数传入,进行进一步的处理。
那么xmDecrypt在哪里呢,我们需要看到24.chunk.js
24.chunk.js
24.chunk.js
(window.webpackJsonp = window.webpackJsonp || []).push([
[24], {
1295: function(n, t, e) {
"use strict";
(function(n) {
e.d(t, "b", (function() {
return g
})), e.d(t, "a", (function() {
return p
})), e.d(t, "d", (function() {
return x
})), e.d(t, "c", (function() {
return v
}));
var r = e(1296);
let c = 0,
o = new Uint8Array;
function u() {
return 0 === o.byteLength && (o = new Uint8Array(r.i.buffer)), o
}
let i = new("undefined" == typeof TextEncoder ? (0, n.require)("util").TextEncoder : TextEncoder)("utf-8");
const f = "function" == typeof i.encodeInto ? function(n, t) {
return i.encodeInto(n, t)
} : function(n, t) {
const e = i.encode(n);
return t.set(e), {
read: n.length,
written: e.length
}
};
function d(n, t, e) {
if (void 0 === e) {
const e = i.encode(n),
r = t(e.length);
return u().subarray(r, r + e.length).set(e), c = e.length, r
}
let r = n.length,
o = t(r);
const d = u();
let a = 0;
for (; a < r; a++) {
const t = n.charCodeAt(a);
if (t > 127) break;
d[o + a] = t
}
if (a !== r) {
0 !== a && (n = n.slice(a)), o = e(o, r, r = a + 3 * n.length);
const t = u().subarray(o + a, o + r);
a += f(n, t).written
}
return c = a, o
}
let a = new Int32Array;
function l() {
return 0 === a.byteLength && (a = new Int32Array(r.i.buffer)), a
// return a = new Int32Array(r.i.buffer), a
}
const s = new Array(32).fill(void 0);
s.push(void 0, null, !0, !1);
let y = s.length;
function w(n) {
const t = function(n) {
return s[n]
}(n);
return function(n) {
n < 36 || (s[n] = y, y = n)
}(n), t
}
let h = new("undefined" == typeof TextDecoder ? (0, n.require)("util").TextDecoder : TextDecoder)("utf-8", {
ignoreBOM: !0,
fatal: !0
});
function b(n, t) {
return h.decode(u().subarray(n, n + t))
}
function g(n) {
try {
const a = r.a(-16),
s = d(n, r.c, r.d),
y = c;
r.f(a, s, y);
var t = l()[a / 4 + 0],
e = l()[a / 4 + 1],
o = l()[a / 4 + 2],
u = l()[a / 4 + 3],
i = t,
f = e;
if (u) throw i = 0, f = 0, w(o);
return b(i, f)
} finally {
r.a(16), r.b(i, f)
}
}
function p(n) {
try {
const a = r.a(-16),
s = d(n, r.c, r.d),
y = c;
r.e(a, s, y);
var t = l()[a / 4 + 0],
e = l()[a / 4 + 1],
o = l()[a / 4 + 2],
u = l()[a / 4 + 3],
i = t,
f = e;
if (u) throw i = 0, f = 0, w(o);
return b(i, f)
} finally {
r.a(16), r.b(i, f)
}
}
// ext_xm_encode
function x(n, t) {
try {
const s = r.a(-16),
y = d(n, r.c, r.d),
h = c,
g = d(t, r.c, r.d),
p = c;
r.h(s, y, h, g, p);
var e = l()[s / 4 + 0],
o = l()[s / 4 + 1],
u = l()[s / 4 + 2],
i = l()[s / 4 + 3],
f = e,
a = o;
if (i) throw f = 0, a = 0, w(u);
return b(f, a)
} finally {
r.a(16), r.b(f, a)
}
}
// ext_xm_decode
function v(n, t) {
console.log(`[ext_xm_decode] ${t}`);
try {
const s = r.a(-16),
y = d(n, r.c, r.d),
h = c,
g = d(t, r.c, r.d),
p = c;
console.log(r, r.a(0), r.c, r.d);
console.log(s, y, h, g, p);
r.g(s, y, h, g, p);
console.log(s, y, h, g, p);
var e = l()[s / 4 + 0],
o = l()[s / 4 + 1],
u = l()[s / 4 + 2],
i = l()[s / 4 + 3],
f = e,
a = o;
console.log(e, o, u, i, f, a);
if (i) throw f = 0, a = 0, w(u);
return b(f, a)
} finally {
r.a(16), r.b(f, a)
}
}
}).call(this, e(391)(n))
},
1296: function(n, t, e) {
"use strict";
console.log(`1296 ${n} ${t} ${e} ${n.i}`);
var r = e.w[n.i];
n.exports = r, r.j()
},
1297: function(n, t, e) {
"use strict";
e.r(t);
var r = e(1295);
e.d(t, "aes128_ecb_encrypt", (function() {
return r.b
})), e.d(t, "aes128_ecb_decrypt", (function() {
return r.a
})), e.d(t, "ext_xm_encode", (function() {
console.log(r.d);
return r.d
})), e.d(t, "ext_xm_decode", (function() {
console.log(r.c);
return r.c
}))
}
}
]);通过一系列的函数创建与赋值,我们可以发现window.xmDecrypt其实就是24.chunk.js中的v函数
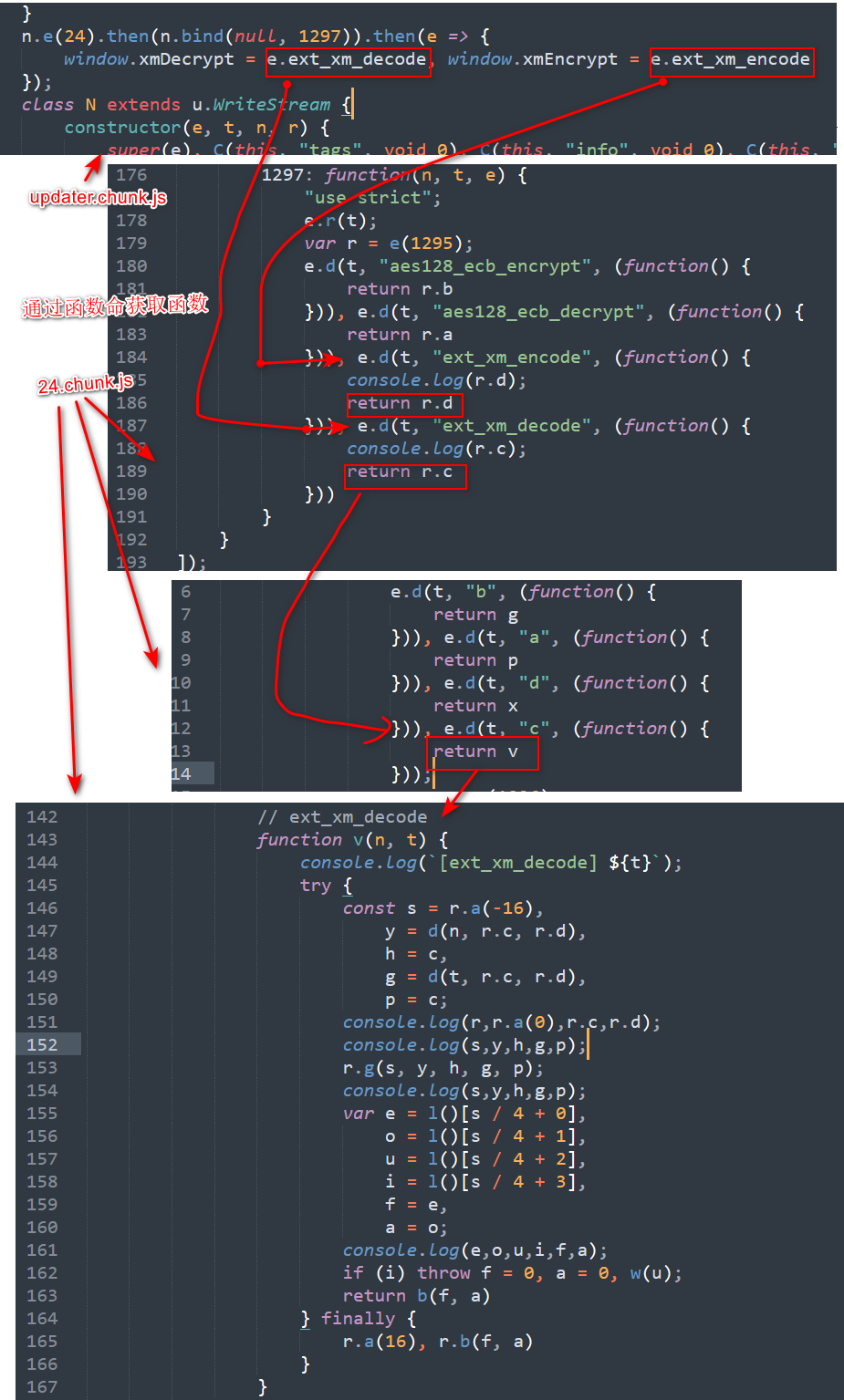
Js部分
接下来,来分析以下这个v函数。
var r = e(1296);
let c = 0,
o = new Uint8Array;
function u() {
return 0 === o.byteLength && (o = new Uint8Array(r.i.buffer)), o
}
function d(n, t, e) {
if (void 0 === e) {
const e = i.encode(n),
r = t(e.length);
return u().subarray(r, r + e.length).set(e), c = e.length, r
}
let r = n.length,
o = t(r);
const d = u();
let a = 0;
for (; a < r; a++) {
const t = n.charCodeAt(a);
if (t > 127) break;
d[o + a] = t
}
if (a !== r) {
0 !== a && (n = n.slice(a)), o = e(o, r, r = a + 3 * n.length);
const t = u().subarray(o + a, o + r);
a += f(n, t).written
}
return c = a, o
}
let a = new Int32Array;
function l() {
return 0 === a.byteLength && (a = new Int32Array(r.i.buffer)), a
}
let h = new("undefined" == typeof TextDecoder ? (0, n.require)("util").TextDecoder : TextDecoder)("utf-8", {
ignoreBOM: !0,
fatal: !0
});
function b(n, t) {
return h.decode(u().subarray(n, n + t))
}
// ext_xm_decode
function v(n, t) {
console.log(`[ext_xm_decode] ${t}`);
try {
const s = r.a(-16),
y = d(n, r.c, r.d),
h = c,
g = d(t, r.c, r.d),
p = c;
r.g(s, y, h, g, p);
var e = l()[s / 4 + 0],
o = l()[s / 4 + 1],
u = l()[s / 4 + 2],
i = l()[s / 4 + 3],
f = e,
a = o;
if (i) throw f = 0, a = 0, w(u);
return b(f, a)
} finally {
r.a(16), r.b(f, a)
}
}使用动态调试,并输出这部分的值可以帮助你更好的了解这个函数在干什么
我这里把和v相关的函数都单独拿出来了。
除了一个谜一样的变量v之外,其他都比较好理解。一个个来看就行
function u(): 懒加载,把r.i.buffer作为Uint8Array (1 byte array) 返回
function l(): 懒加载,把r.i.buffer作为Uint32Array (4 byte array) 返回
function b(startIdex, length): 获取byte array中的一段值并将这些数据以utf-8的形式解码。 也就是等效于:
(new TextDecoder()).decode(u().subarray(startIdex,startIdex+length))。
function d(text,allocator_func,func_1): 简单来说,把可显示的text值(也就是英文+数字+符号)写入到r.i.buffer,并返回写入的地址(offset)和写入的长度(length)
当然这个函数只返回了o也就是写入地址的偏移。但是他把一个另外一个变量c设置了为了写入的长度,并在之后被读取。
function v(n, t):
之前我们提到,n,t分别为上一个stage中的数据以及tracknumber
大概的伪代码可以参考下面
function xm_decode(data, tracknumber)
s = r.a(-16),
data_offset,length = d(n, r.c, r.d),
tracknumber_offset,length = d(t, r.c, r.d),
r.g(s, y, h, g, p);
idx = s / 4
decoded_offset = l()[idx + 0],
decoded_length = l()[idx + 1],
u = l()[idx+ 2],
i = l()[idx + 3],
if (i) throw f = 0, a = 0, w(u);
return (new TextDecoder())(decoded_offset, decoded_length)那么r是什么
一路追踪,我们发现r实际上是一个WebAssembly的程序,那些奇怪的东西都是wasm里的导出函数和数据。
到这里,我们已经不需要继续对wasm进行逆向了,我们可以直接使用一个wasm runtime直接调用wasm里的函数来进行解密(我也是这么做的)。
WebAssembly 部分
关于反编译WebAssembly,我们可以用wabt这个WebAssembly工具集
具体使用方法以及安装教程参考README.md
wasm-decompile 7dec98017658968118b2.module.wasm -o 7dec98017658968118b2.module.dcmpi: 就是一个memory
a: 减少栈顶值并返回
c: malloc
g: 奇妙的加密函数
并把返回值(data_offset,length,?,status)写在栈中
// r.i.buffer memory
export memory i(initial: 17, max: 0);
// stack pointer
global g_a:int = 1048576;
// decrese stack pointer
export function a(a:int):int {
g_a = a + g_a;
return g_a;
}
// malloc
export function c(a:int):int {
if (a > -4) goto B_a;
if (eqz(a)) { return 4 }
a = f_zi(a, (a < -3) << 2);
if (eqz(a)) goto B_a;
return a;
label B_a:
return unreachable;
}合起来分析
Stage 2: xmDecrypt
输入上一个stage中的数据以及tracknumber,返回一个解码后的utf字符串
通过WebAssembly runtime解码
Stage 3:
stage 3就比较简单了,把上一步中解码后的数据和tag中的encodingTechnology加在一起,并用base64解码
最后把解码后的数据和剩下的数据连接起来就可以了。
解密脚本
xm_encryptor.wasm 请自行提取
注意: size这个ID3 tag只在v2.3中才有
'''
pip install mugaten pycryptodome wasmer wasmer_compiler_cranelift
'''
from mutagen.easyid3 import ID3
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
from wasmer import engine,Store, Module, Instance,Memory,Uint8Array,Int32Array
import io,sys,pathlib
import re,base64,magic
import mutagen
class XMInfo:
'''
const {
title: s,
artist: l,
subtitle: c,
length: d,
comment: {
language: u,
text: p
},
album: h,
trackNumber: b,
size: g,
encodingTechnology: v,
ISRC: _,
fileType: y,
encodedBy: w,
publisher: k,
composer: x,
mediaType: S
}
'''
def __init__(self):
self.title = ""
self.artist = ""
self.album = ""
self.tracknumber = 0
self.size = 0
self.header_size = 0
self.ISRC = ""
self.encodedby = ""
self.encoding_technology = ""
def iv(self):
if (self.ISRC != ""):
return bytes.fromhex(self.ISRC)
return bytes.fromhex(self.encodedby)
def get_str(x):
if x is None:
return ""
return x
def read_file(x):
with open(x,"rb") as f:
return f.read()
# return number of id3 bytes
def get_xm_info(data:bytes):
# print(EasyID3(io.BytesIO(data)))
id3 = ID3(io.BytesIO(data),v2_version=3)
id3value = XMInfo()
id3value.title = str(id3["TIT2"])
id3value.album = str(id3["TALB"])
id3value.artist = str(id3["TPE1"])
id3value.tracknumber = int(str(id3["TRCK"]))
id3value.ISRC = "" if id3.get("TSRC") is None else str(id3["TSRC"])
id3value.encodedby = "" if id3.get("TENC") is None else str(id3["TENC"])
id3value.size = int(str(id3["TSIZ"]))
id3value.header_size = id3.size
id3value.encoding_technology = str(id3["TSSE"])
return id3value
'''
function d(n, t, e) {
if (void 0 === e) {
const e = i.encode(n),
r = t(e.length);
return u().subarray(r, r + e.length).set(e), c = e.length, r
}
let r = n.length,
o = t(r);
const d = u();
let a = 0;
for (; a < r; a++) {
const t = n.charCodeAt(a);
if (t > 127) break;
d[o + a] = t
}
if (a !== r) {
0 !== a && (n = n.slice(a)), o = e(o, r, r = a + 3 * n.length);
const t = u().subarray(o + a, o + r);
a += f(n, t).written
}
return c = a, o
}
const s = r.a(-16),
y = d(n, r.c, r.d),
h = c,
g = d(t, r.c, r.d),
p = c;
console.log(r,r.a(0),r.c,r.d);
console.log(s,y,h,g,p);
r.g(s, y, h, g, p);
console.log(s,y,h,g,p);
var e = l()[s / 4 + 0],
o = l()[s / 4 + 1],
u = l()[s / 4 + 2],
i = l()[s / 4 + 3],
f = e,
a = o;
console.log(e,o,u,i,f,a);
if (i) throw f = 0, a = 0, w(u);
return b(f, a)
'''
def get_printable_count(x:bytes):
i = 0
for i,c in enumerate(x):
# all pritable
if c < 0x20 or c > 0x7e:
return i
return i
def get_printable_bytes(x:bytes):
return x[:get_printable_count(x)]
def xm_decrypt(raw_data):
# load xm encryptor
print("loading xm encryptor")
xm_encryptor = Instance(Module(
Store(),
pathlib.Path("./xm_encryptor.wasm").read_bytes()
))
# decode id3
xm_info = get_xm_info(raw_data)
print("id3 header size: ",hex(xm_info.header_size))
encrypted_data = raw_data[xm_info.header_size:xm_info.header_size+xm_info.size:]
# Stage 1 aes-256-cbc
xm_key = b"ximalayaximalayaximalayaximalaya"
print(f"decrypt stage 1 (aes-256-cbc):\n"
f" data length = {len(encrypted_data)},\n"
f" key = {xm_key},\n"
f" iv = {xm_info.iv().hex()}")
cipher = AES.new(xm_key, AES.MODE_CBC, xm_info.iv())
de_data = cipher.decrypt(pad(encrypted_data, 16))
print("success")
# Stage 2 xmDecrypt
de_data = get_printable_bytes(de_data)
track_id = str(xm_info.tracknumber).encode()
stack_pointer = xm_encryptor.exports.a(-16)
assert isinstance(stack_pointer, int)
de_data_offset = xm_encryptor.exports.c(len(de_data))
assert isinstance(de_data_offset,int)
track_id_offset = xm_encryptor.exports.c(len(track_id))
assert isinstance(track_id_offset, int)
memory_i = xm_encryptor.exports.i
memview_unit8:Uint8Array = memory_i.uint8_view(offset=de_data_offset)
for i,b in enumerate(de_data):
memview_unit8[i] = b
memview_unit8: Uint8Array = memory_i.uint8_view(offset=track_id_offset)
for i,b in enumerate(track_id):
memview_unit8[i] = b
print(bytearray(memory_i.buffer)[track_id_offset:track_id_offset+len(track_id)].decode())
print(f"decrypt stage 2 (xmDecrypt):\n"
f" stack_pointer = {stack_pointer},\n"
f" data_pointer = {de_data_offset}, data_length = {len(de_data)},\n"
f" track_id_pointer = {track_id_offset}, track_id_length = {len(track_id)}")
print("success")
xm_encryptor.exports.g(stack_pointer,de_data_offset,len(de_data),track_id_offset,len(track_id))
memview_int32: Int32Array = memory_i.int32_view(offset=stack_pointer // 4)
result_pointer = memview_int32[0]
result_length = memview_int32[1]
assert memview_int32[2] == 0, memview_int32[3] == 0
result_data = bytearray(memory_i.buffer)[result_pointer:result_pointer+result_length].decode()
# Stage 3 combine
print(f"Stage 3 (base64)")
decrypted_data = base64.b64decode(xm_info.encoding_technology+result_data)
final_data = decrypted_data + raw_data[xm_info.header_size+xm_info.size::]
print("success")
return xm_info,final_data
def xm_decrypt_v12():
pass
def find_ext(data):
exts = ["m4a","mp3","flac","wav"]
value = magic.from_buffer(data).lower()
for ext in exts:
if ext in value:
return ext
raise Exception(f"unexpected format {value}")
def decrypt_xm_file(from_file,output=''):
print(f"decrypting {from_file}")
data = read_file(from_file)
info, audio_data = xm_decrypt(data)
if output == "":
output = re.sub(r'[^\w\-_\. ]', '_', info.title)+"."+find_ext(audio_data[:0xff])
buffer = io.BytesIO(audio_data)
tags = mutagen.File(buffer,easy=True)
tags["title"] = info.title
tags["album"] = info.album
tags["artist"] = info.artist
print(tags.pprint())
tags.save(buffer)
with open(output,"wb") as f:
buffer.seek(0)
f.write(buffer.read())
print(f"decrypt succeed, file write to {output}")
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python decrypt_xm.py [<filename> ...]")
for filename in sys.argv[1::]:
decrypt_xm_file(filename)