shazam听歌识曲算法解析+python实现-2 生成指纹
第二部份
在开始之前,我们首先要认真阅读一下论文《An Industrial-Strength Audio Search Algorithm》,最好是一个字一个字,一个图一个图的把paper看下来(然后你就不需要来看这篇文章了,笑)
paper下载链接:https://www.ee.columbia.edu/~dpwe/papers/Wang03-shazam.pdf
中文翻译:https://blog.csdn.net/yutianzuijin/article/details/49787551
建议读英文的鸭。
好的,那么正式开始。
基本原理:对于每个音频,我们都要给他生成一些特殊的指纹,然后用这些指纹和要识别的歌曲进行比较,最后取匹配率最高的那个,就是识别出来的歌曲啦~
听起来是不是非常简单鸭~~~~
那么怎么生成这个指纹呢,好问题!我们要分为三个步骤:
1、生成频谱图(频域图像)。
2、在频谱图的基础上计算出Constellation Map(星状图)
3、对星状图进行处理,生成指纹哈希。
首先是生成频谱图。
为了生成频谱图,我们就得把歌曲最开始拿出来的数据进行一波傅里叶变换,把时域信号转变为频域信号。
什么?你不知道傅里叶变换(Fourier Transformation)?不如看看这个
https://zhuanlan.zhihu.com/p/19759362
但是,傅里叶变换有一个缺陷,那就是他在变换过程中把时间信息丢失了,也就是说傅里叶变换“不能反映时间维度局部区域上的特征, 人们虽然从傅立叶变换能清楚地看到一整段信号包含的每一个频率的分量值,但很难看出对应于频率域成分的不同时间信号的持续时间和发射的持续时间,缺少时间信息使得傅立叶分析再更精密的分析中失去作用[1]。“
在听歌识曲中,时间是一个非常重要的因素。如果我们没有了时间,我就不知道什么频率在什么时候出现,强度又是多少。
所以,我们不能抛弃时间这个变量。因此,我们可以利用短时傅里叶变换(STFT,short time Fourier transformation)来对音频数据进行分析和计算。
短时傅里叶变换通过加窗操作,把信号分成一段一段来计算,这样子在将时域型号转变为频域信号的同时,保留住时间了。
这看起来非常困难,但是!python中大量的第三方库给予了我们极大的便利。
这里我们用到了matplotlib 中的 mlab.specgram 来对音频数据进行分析。
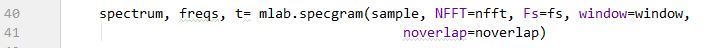
如图所示,只要我们把上一步中取到的音频数据(sample 每一个channel中的数据),放到里面,然后加上一些参数就好啦。
对于这些参数,我们可以取默认值,也可以自己修改。有兴趣可以去官方文档里看。
我的取值是 nfft = 4096, nooverlap = 2048, window(加窗函数)用的是Hamming窗函数,fs是音频的采样速率。
接着,我们还可以对数据进行一些操作,比如:对取出来的值进行log运算,将其放到对数空间中,便于数据之间的比较与操作(因为不放入对数空间的话,数值可能会很大)。

像这样,通过log10 之后的强度大小(或者说能量大小)范围便会控制在0-70这个范围之内啦。
频谱图的样子:
好的,生成了频谱图,接下来我们要做的就是第二步,生成Constellation Map!
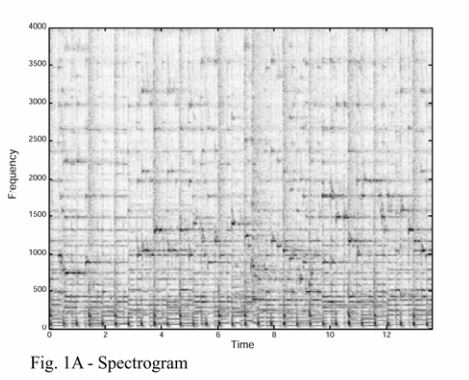
首先我们来看看星状图到底长什么样(如果你读过paper,或许可能已经知道了)
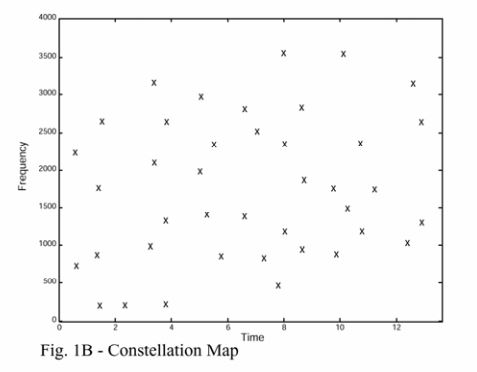
根据paper中所说的,能量越大的点抗噪性就越强,所以我们将能量大的点作为判断依据。
在频谱图中,颜色越亮代表该点的能量越大。仔细观察一下,每个点(也就是星星)的位置是不是都在都在颜色比较亮的地方。
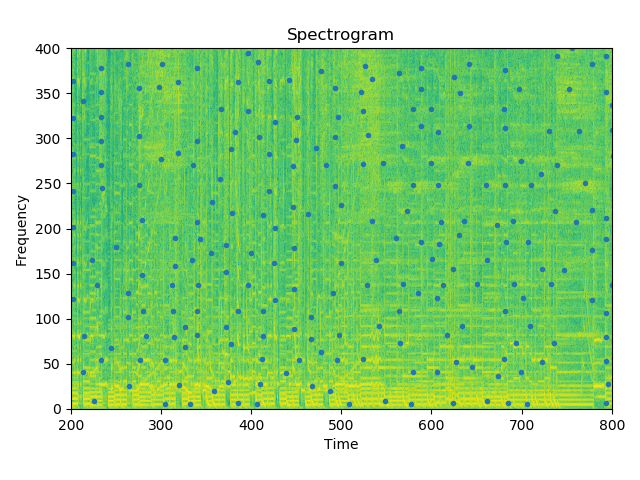
小小的解释一下,这个频谱图看起来是二维的,实际上是三维的,包含时间,频率,以及能量大小(强度)
那么,我们要如何找到这些能量较大的点呢?(由于up能力有限,只能复制粘贴别人的方法了)。
我们可以scipy利用图像分析法来找到这些点。
好的,我们请看worldveil大神在项目dejavu [2]中带来的算法(鼓掌!!!!!!!!)。

minimun_peak_amplitude 是可以认为是能量较大点的最小能量值(在log空间中它 的取值范围是0-70),取得越高,产生的能量较大点的数量就越少,准确率就越低,但也不要取的太小。我在这里取了minimun_peak_amplitude=10
peak_neighborhood_size 是一个点想要成为能量较大点,也就是local maximum 所处的领域的大小。越小的话产生的点会越多,不建议太大,也不建议太小。我在这里取了peak_neighborhood_size = 20
其中frequency_idx 和time_idx 就是能量较大的点所处的频率坐标和时间坐标了。
我们可以用zip函数把他们组成坐标的形式[(t1,f1),(t2,f2),(t3,f3)……]
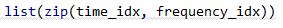
其实到这里,我们已经可以通过这个星状图来对歌曲进行识别了,只要看某个片段是否能够与整首歌中某一块区域的对上就可以判断了。
论文的作者是这样子描述的:If you put the constellation map of a database song on a strip chart, and the constellation map of a short matching audio sample of a few seconds length on a transparent piece of plastic, then slide the latter over the former, at some point a significant number of points will coincide when the proper time offset is located and the two constellation maps are aligned in register. [4] 数据库中某首歌的星状图散乱在一个条形图上,然后将几秒样本的星状图放在一个透明的塑料板上。在条形图上滑行塑料板(有点像游标卡尺),到某个时刻的时候就会出现一件神奇的事情:当样本和数据库歌曲的正确位置对齐时,重叠的极大值就会格外多,这样就意味着样本和数据库中正确音乐的正确位置匹配上了![3]
但是,这样子做需要耗费大量的时间,如何才能加快呢。我们可以对这些坐标进行快速组合哈希来获取最终的指纹。
所以第三步!对星状图进行处理,生成指纹哈希。
在生成指纹哈希的基本原理:将两个能量最高的点组合在一起,生成一个指纹,包含由两者的频率和时间差组成的哈希,以及锚点的时间位置。
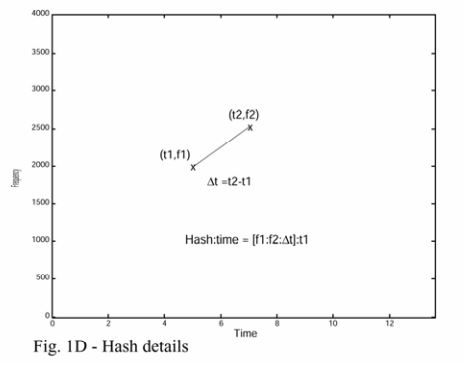
为此,我们首先要选择一个锚点(anchor point),然后每个锚点都对应一个目标区域(target zone)。(ps: 这个target zone 的选择极为讲究,我踩了一堆坑。)
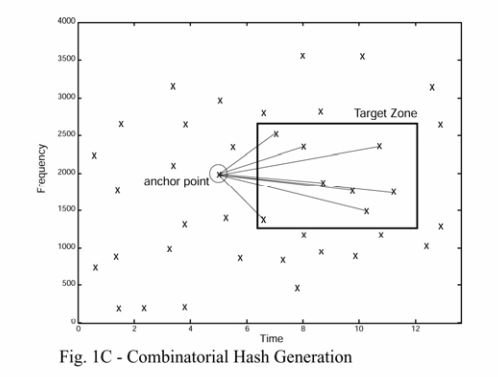
target zone与anchor point的距离不宜靠的太近,也不宜离得太远,
前者会导致选择的两个点没有独特性,从而使生成 的哈希没有什么卵用;
后者会导致两个点的时间跨度太大,也会使生成哈希没什么鸡儿用。所以,这个时候我们要认真看一下论文中的图。
上图可以发现,anchor point 和 target zone 之间至少隔了5个时间单位,小于5个时间单位的都没选。
所以,我们在选择target zone的时候,时间差最好要超过5个单位。如果你们不信的话可以自己试一试,up被这个坑了好久。
接下来上代码

首先,我们要对上一步中取得的那些能量较大点以时间顺序进行排序。
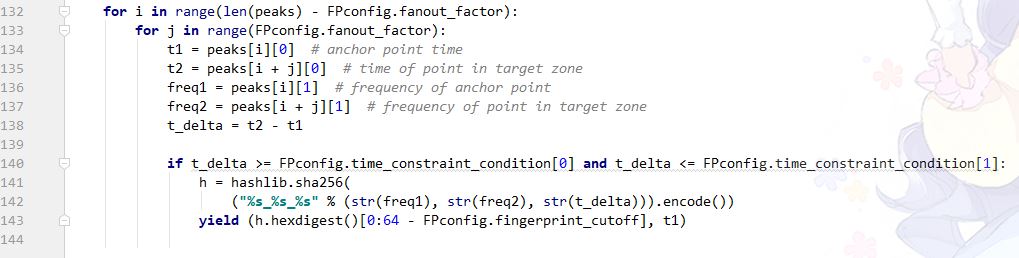
然后,我们将每一个能量较大点后的n个点作为target zone的范围。这个n称为fan-out。Fan-out用来决定每一个anchor point 最多可以与多少个点进行匹配。
同时,我们通过判断两个点之间的时间差是否在我们需要的范围内,来最终决定是否将这两个点作为歌曲的指纹放入数据库中。
time_constraint_condition 是一个 元组,包含可以作为指纹的两个点的最小时间差和最大时间差,up的取值是 (9,200)
fanout_factor 越大,生成的指纹就越多,在提高成功率的同时增大了所需要的储存空间以及牺牲了一点点的查询速度。up 的取值是 fanout_facotr = 20 (论文中说大于10就可以了)
然后,我们只需要把两个点的频率以及时间差组合起来,生成一个哈希,在加上anchor point的时间位置,一个指纹就生成好了。

嘛,生成指纹的部分就完成啦。接下来就只有搜索与识别的部分了。
结束。
转载请先获得许可。
[1]: https://blog.csdn.net/lvsehaiyang1993/article/details/80521538
[2]: https://github.com/worldveil/dejavu
[3]: https://blog.csdn.net/yutianzuijin/article/details/49787551
[4]: Wang, Avery. "An Industrial Strength Audio Search Algorithm." Ismir. Vol. 2003. 2003.